Under Review
2026
Optimizing Semantic Retrieval for Bengali: A Comparative Analysis of Monolingual and Multilingual Embeddings with Matryoshka Representation Learning
Authors: K. Debanath and A.Y. Srizon
Submitted to: Transactions on Asian and Low-Resource Language Information Processing (TALLIP)
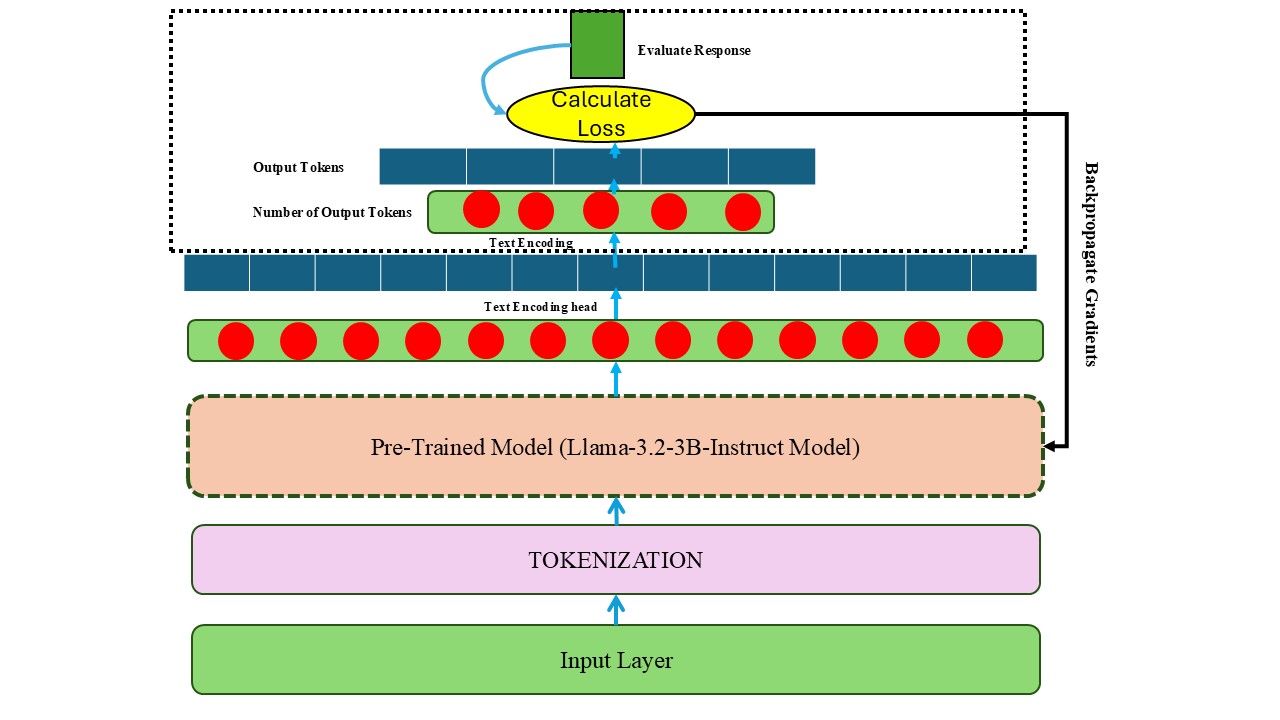
Abstract—Effective semantic retrieval remains the primary bottleneck for Bengali Retrieval-Augmented Generation (RAG) systems. While general-purpose multilingual models exist, they often lack the semantic alignment required for high-precision tasks. This paper presents a comparative study of three embedding architectures—monolingual (shihab17), distilled multilingual (distiluse), and paraphrase-focused (mpnet)—to identify the strongest retrieval foundation for Bengali. The models are fine-tuned on the BanglaRQA dataset with a composite objective combining Multiple Negatives Ranking Loss and Matryoshka Representation Learning (MRL). Results show that architectural choice is decisive: the fine-tuned mpnet model achieves an NDCG@10 of 0.8114 and statistically outperforms the monolingual baseline (p < 0.001). Beyond retrieval quality, efficiency analysis for low-resource deployment shows that MRL-trained MPNet preserves 96% of retrieval effectiveness at 128 dimensions, reducing storage cost by 83% without meaningful accuracy loss.
CCS Concepts: Computing methodologies → Natural language processing; Neural networks. Information systems → Retrieval models and ranking.
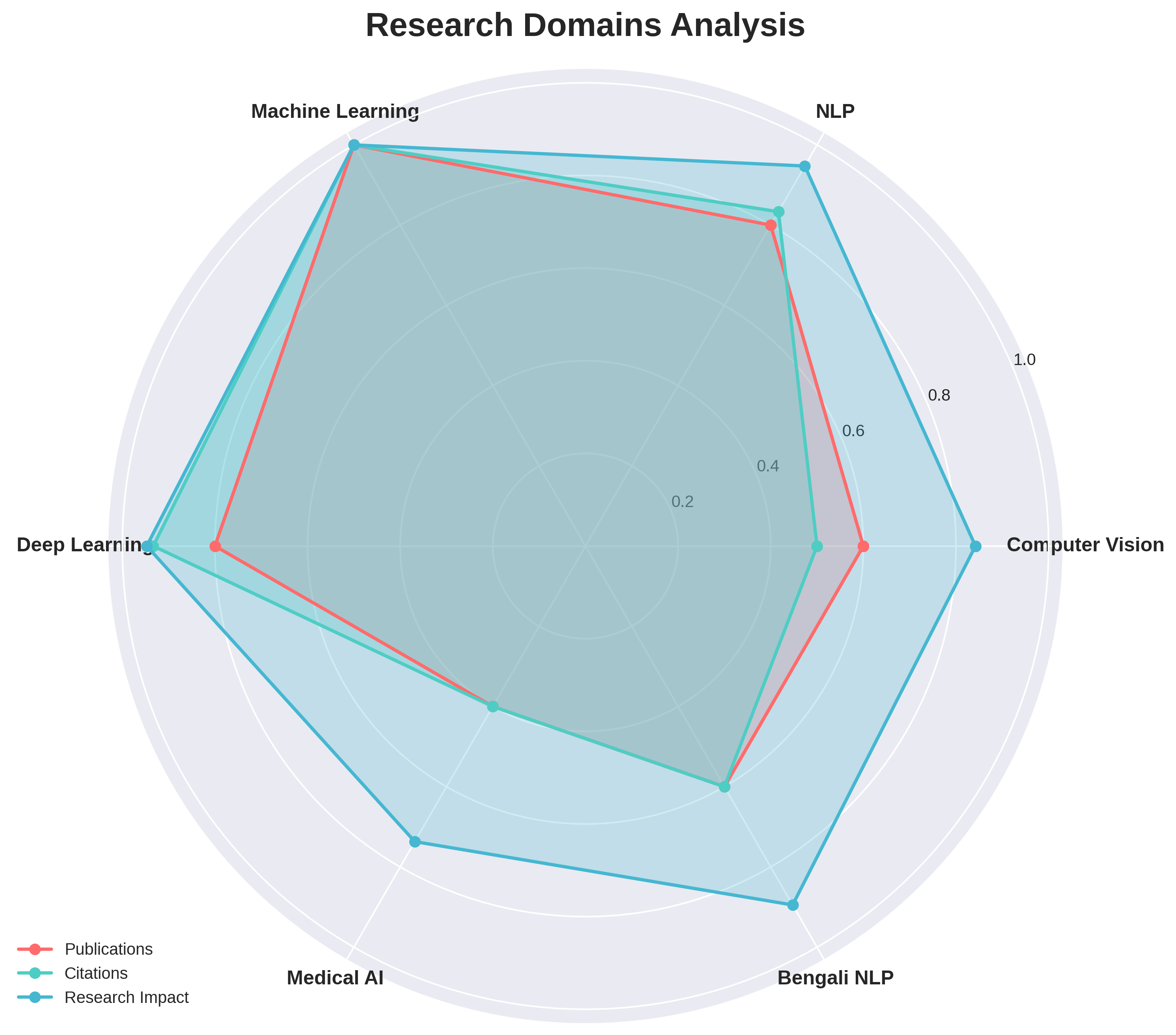
Bengali NLP
Semantic Retrieval
Monolingual vs Multilingual Embeddings
Matryoshka Representation Learning
Sentence Embeddings
RAG